Programowanie w SAS 4GL
W Systemie SAS językiem, którym będziemy się posługiwać jest 4GL (Fourth Generation Language). Jest to wyspecjalizowany język do przetwarzania danych w formie tabelarycznej. Stosuje się w nim koncepcje programowania proceduralnego.
Każdy program w języku SAS 4GL składa się z bloków (ang. Step), które wykonywane są sekwencyjnie. Wpierw wszystkie instrukcje są kompilowane, a następnie wykonywane.
Kompilacja i wykonywanie programu jest również wykonywane sekwencyjnie. Komunikacja między blokami może odbywać się za pomocą makrozmiennych, makroprogramów lub z wykorzystaniem pośrednich zbiorów.
Pierwszy program
data dane.a; /* nazwa zbioru wynikowego zapisanego do biblioteki work */
x=4; /* zmienna x o jednej obserwacji */
run;
Programy w 4GL dziela sie na bloki dwóch rodzajów: tzw. DATA Stepy i PROC Stepy. Powyżej widzimy przykład DATA Stepu, który zawsze zaczyna sie slowem kluczowym DATA i kończy słowem RUN. Każde polecenie w jezyku 4GL musi byc zakończone średnikiem. Efektem działania powyzszego kodu jest tabela o nazwie a zapisanej do biblioteki work, z jedną kolumną o nazwie X i jedną wartością w kolumnie wynoszącą 4.
Uruchom kod i sprawdź kolorowanie składni.
data dane.a;
x=4
run;
Fizyczny podział na linie nie ma znaczenia, gdyż kompilowana jest linia do napotkania znaku średnika. Wielkość liter użytych w kodzie programu (z wyjątkiem porównywania wartości zmiennych tekstowych) jest bez znaczenia.
Typy danych
W jezyku 4GL występują tylko dwa typy zmiennych: numeryczne i tekstowe.
Dodajmy więcej zmiennych i może jakiś tekst. Separatorem dziesiętnym jest kropka.
data dane.b;
x=2;
y=7.5;
z='abc';
run;
Atrybuty zmiennych
- Nazwa: do 32 znaków, pierwszym znakiem musi być litera lub _
- Typ: numeryczny, znakowy
- Długość
- Format
- Informat
- Etykieta: do 256 znaków
- Typ indeksu: brak, prosty, złożony, oba
- Atrybuty rozszerzone
Typ danych – numeryczny
- Stałanumeryczna: 10, 5.3, -5
- Zmienna numeryczna - Długość 3-8 bajtów oraz przechowuje wartości całkowitoliczbowe i zmiennoprzecinkowe
Typ danych - znakowy
- Stała znakowa - ’tekst 1’, "tekst 2"
- Zmienna znakowa - Długość 1-32 767 bajtów, Czuła na wielkość liter
Braki danych
data dane.c;
x=0;
y=1/x;
run;
Zmodyfikujmy trochę nasz program
data dane.a1;
x=5;
x=200;
run;
Potrzebna nam bedzie instrukcja, ktora wymusza zapisanie wartosci do zbioru wynikowego - instrukcja OUTPUT:
data dane.a2;
x=5;
output;
x=200;
output;
run;
Zapisywanie większej ilości wartości i zmiennych tym sposobem będzie trwało raczej długo.
Zadanie domowe - jakie wyniki wygenerują kody?
data a;
x=5;
output;
run;
data a;
x=5;
output;
x=200;
run;
data a;
x=5;
y=7;
output;
x=6;
y=8;
output;
run;
Prosta pętla DO END
data dane.zbior;
DO i=1 to 10;
x=floor(100*ranuni(0));
output;
end;
run;
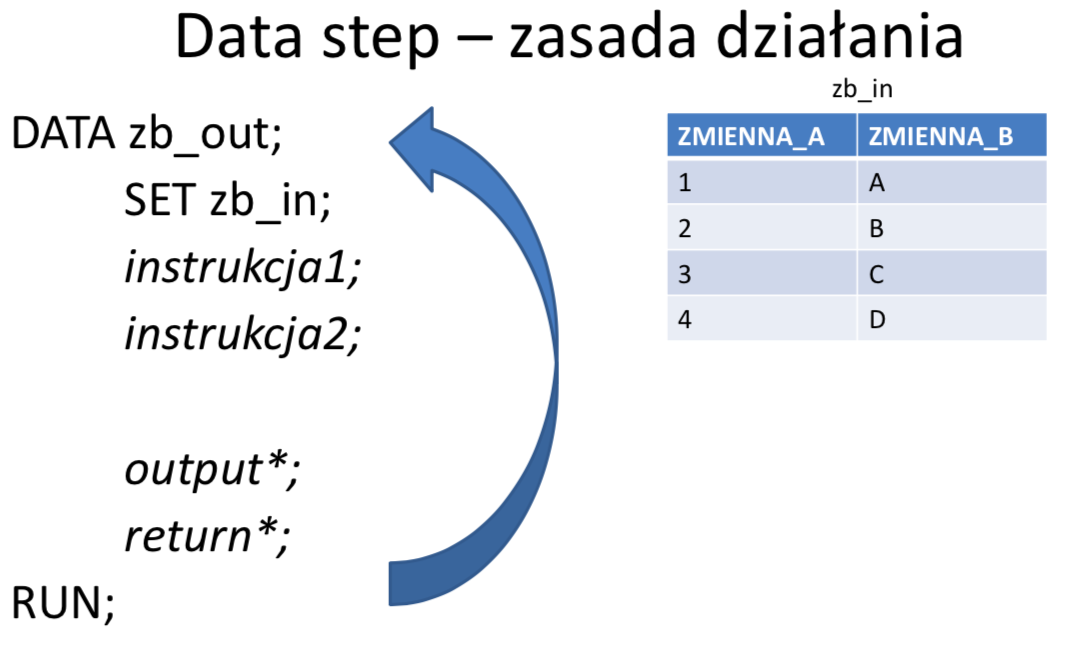
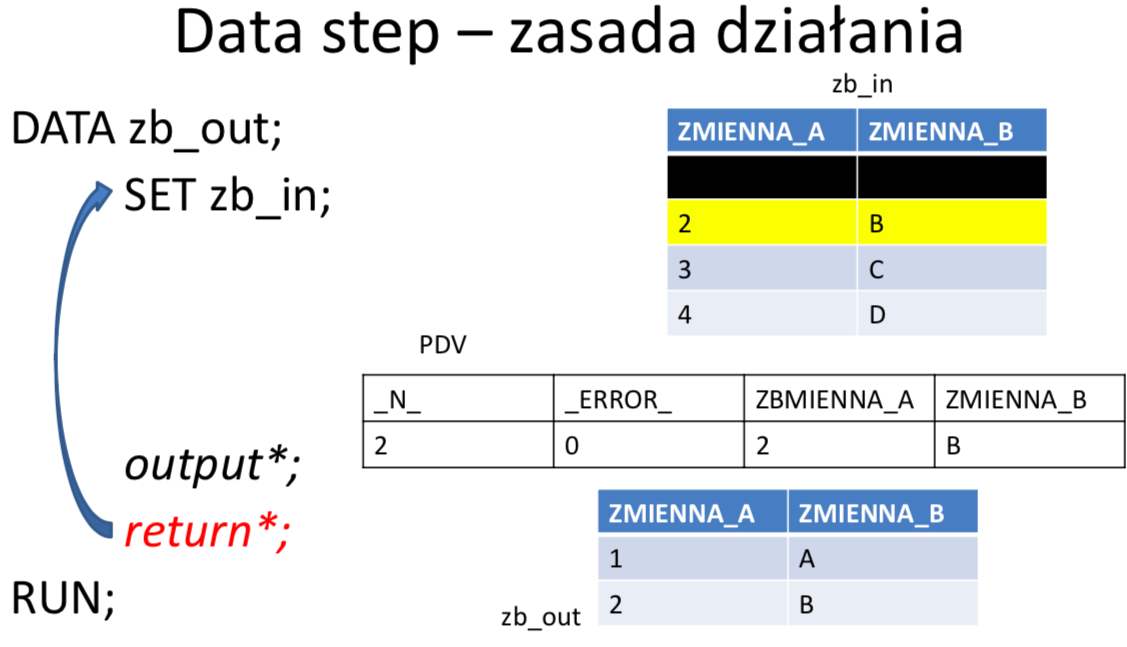
Parametr SET w DATA STEPIE
data dane.zbior_copy;
set work.zbior;
run;
Powyższy program to metoda, którą możesz skopiować cały zbiór określony w SET do zbioru określonego w DATA.

Data Step jest blokiem odpowiedzialnym za przetwarzanie sekwencyjne
Instrukcja SET występuje tylko w DATA Stepie
Domyślnie instrukcja SET czyta wszystkie obserwacje ze zbioru począwszy od pierwszej.
W przypadku gdy chcesz iterować po plikua nie po tabeli SET trzeba zamienić na INFILE.
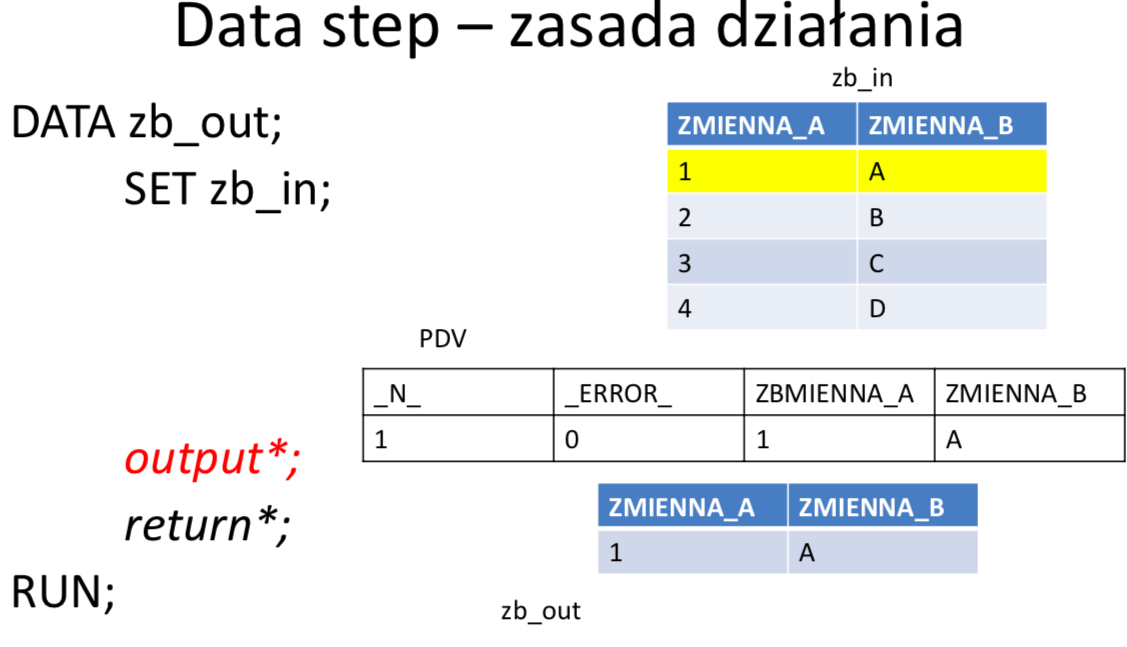
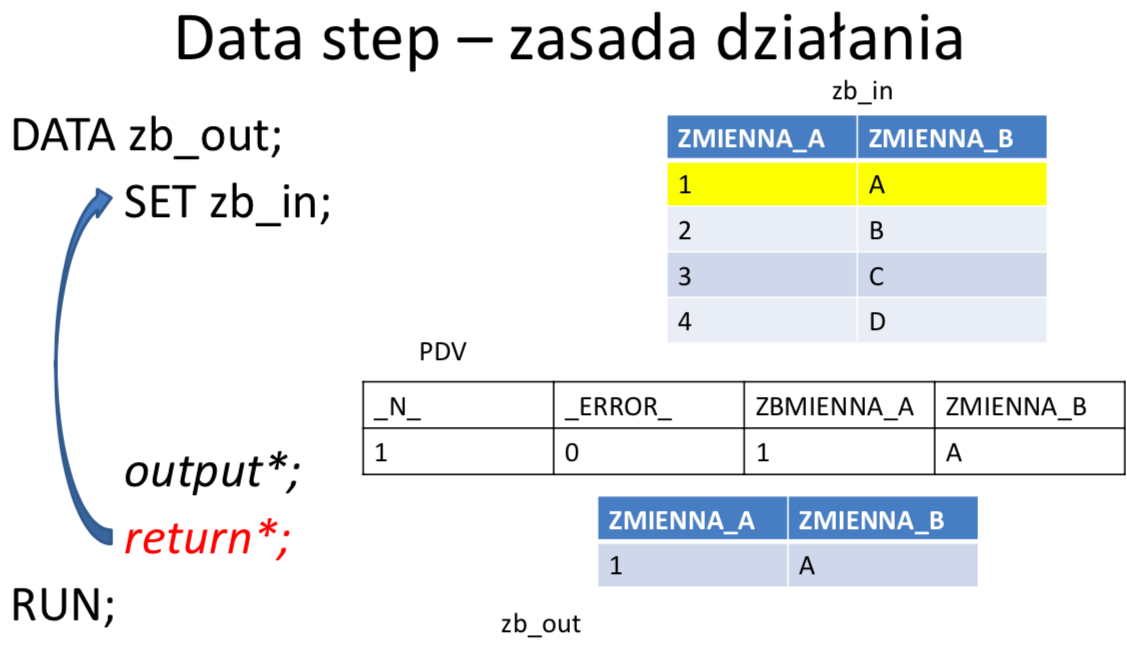
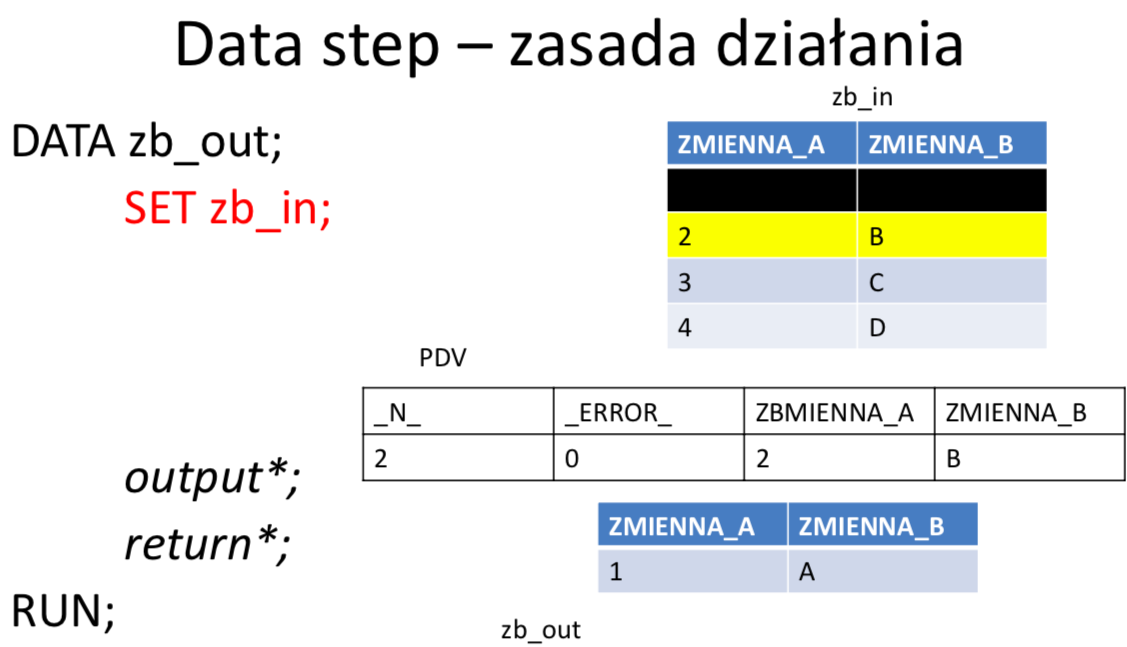
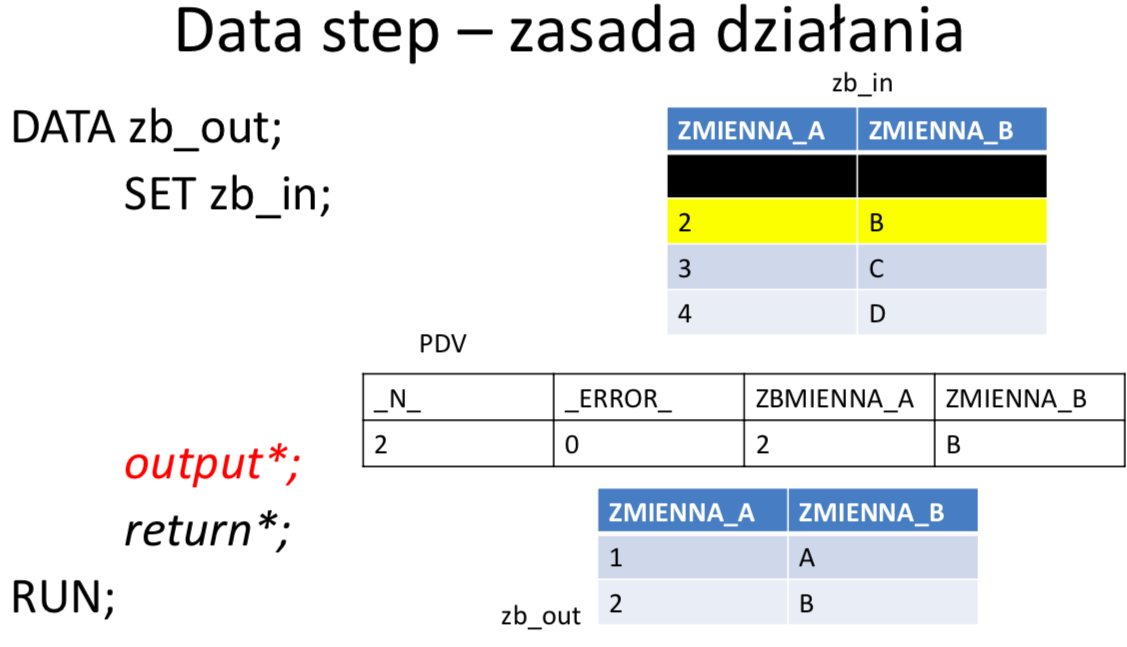
W ramach DATA STEP-u tworzona jest automatycznie pętla główna (ang. implicit loop), w obrębie której: czytana jest kolejna obserwacja z wejściowego zbioru danych (lub wiersz z wejściowego pliku płaskiego), wykonywane są instrukcje będące treścią danego kroku, finalna postać obserwacji zapisywana jest do zbioru wynikowego. Domyślnie pętla główna wykonywana jest dla każdej obserwacji w zbiorze wejściowym. W przypadku, gdy w DATA STEPIE nie ma żadnej instrukcji czytającej ze zbiorów, pętla główna wykonuje się tylko jeden raz.
Chcemy każdą wartość występującej zmiennej X zwiększyć o 100.
data dane.zbior_m;
set zbior;
x=x+100;
run;
Nie jest nam potrzebna żadna dodatkowa pętla !
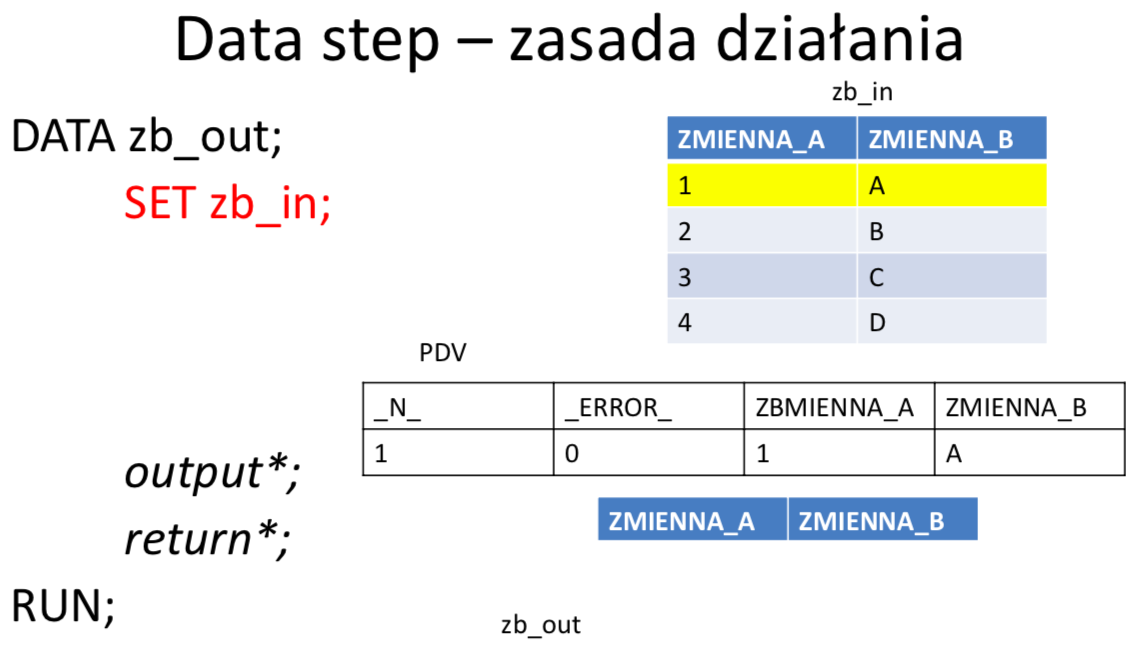
Wektor PDV (Program Data Vector)
PDV jest strukturą tworzoną w pamieci w trakcie kompilacji DATA STEPu. Jest to wektor (jednowymiarowa tablica) zawierająca zmienne istniejące w DATA STEPIE, tzn. zmienne, które istnieją w zbiorze (zbiorach) wejściowym, jak i wszelkie pozostałe zmienne zadeklarowane w kodzie. Przed rozpoczęciem działania DATA STEPU wszystkie zmienne są inicjalizowane na brak danych, następnie podczas wykonywania instrukcji poszczególne wartości nadpisują zawartości wektora. Domyślnie wartości zmiennych, które nie pochodzą ze zbiorów wejściowych, na początku każdej iteracji DATA STEPU są inicjalizowane na braki danych. Jeżeli nie zadecydowano inaczej to po zakończeniu każdego obrotu pętli głównej cała zawartość PDV jest zapisywana do zbioru wynikowego tworząc w nim kolejną obserwację. Zmienne pojawiają się w wektorze PDV w kolejności ich wystąpienia w DATA STEPIE i dokładnie w tej kolejności trafiają do zbioru wynikowego. Wektor PDV zawiera dodatkowo zmienne automatyczne, które nie są zapisywane do zbioru wyjściowego ale mogą być wykorzystane podczas przetwarzania, np.:
- _N_ - zawiera numer bieżącej iteracji data stepu
- _ERROR_-sygnalizujępojawieniesiębłędupodczasprzetwarzania.Domyślnąwartością jest 0 co oznacza, że błędy nie wystąpiły. Kiedy pojawi się jeden lub więcej błędów, zmienna przyjmuje wartość 1.

data _null_;
a = 1;
put 'a= ' a;
put a;
run;
data _null_;
a = 3;
put 'wektor PDV = ' _all_;
run;
Tworzenie zmiennych
Zmienne tworzymy przez przypisanie bądź użycie instrukcji length
data dane.zmienne;
length txt1 txt2 $12;
length n1 n2 n3 8;
txt3= "Sebastian Zając";
n4 = 123;
run;
Istnieje jeszcze retain
data dane.ret_test;
retain a 0;
length b $5;
b='to jest bardzo dlugi napis';
a = a+1;
put a;
put _all_;
run;
Przykład !
data _null_;
length wiersz 8;
set sashelp.class;
wiersz = wiersz +1;
put wiersz;
run;
A teraz inaczej
data _null_;
length wiersz 8;
set sashelp.class;
retain wiersz 0;
wiersz = wiersz +1;
put wiersz;
run;